|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
H18/02/06記述
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ●PC-9801series 高速描画の話1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ゲームアプリケーションに限らず、描画の高速性は大きなアドバンテージになります。インターネットサイト閲覧用ソフト(ブラウザ)でも、表示の高速性をウリにしているものがあるように、これは昔も今も変わりません。ただ、CPUの処理速度が十分になかった時代、高速描画は今以上に大きな意味を持っていました。ゲームの場合、それは「遊べるか、遊べないか」を決定するほど重要なことだったのです。 今回はPC-9801全盛時代、CPUがV30-10MHz〜i486-40MHzくらいの頃の高速テクニックを紹介していきます。もちろん、それ以降でも有効なのですが、Pentium(60MHz〜)になるとCPUの内部構造が大きく変わり、また別の技法が有効になったりするため、敢えて時代を限定してお話ししてまいります。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 01:高速画面クリア | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| これはもう、しょっちゅう使用する処理のひとつです。画面全体(640×400pixel)を単一色で塗りつぶす処理をいいます。マシンによっては、ハードウェアでクリアできるものもありますが、PC-9801にはそのような機能はありません。ソフトウェアでV-RAMにクリアデータを書き込んでいく必要があります。ごく単純に考えてCでコーディングすると、リスト1のようになります。ちなみに、コンパイラはBorland C++ 3.1を想定しています。 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
このように、順次4枚のV-RAMプレーンに16ビット単位(unsigned int)でクリアデータを書き込んでいます。かなりの作業量であることは推測できると思います。しかし、これをさらに高速化しろと言われるとキツいものがあります。 そこで出番の回ってくるのがGRCG、グラフィックチャージャーです。Nr.2のビートバイスのところで少し説明しましたが、1プレーン分のアクセスで、4プレーンにアクセスしてくれるハードウェアです。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ここではわかりやすいようにCで記述してありますが、アセンブラで最適化すればさらに高速化します。コンパイラの最適化性能に大きく左右されますが、8086系CPUにはOUTSやSTOSWといったストリング命令があるので、これらを使用するとよいでしょう。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| と、ここで終わるとありきたりな話になってしまいます。これで満足せずに粘って考えてみます。GRCGを使用する場合、書き込むデータは何でも構わないというところに着目します。とにかく高速に書き込み動作さえできればよいわけですから、CPUのメモリに対しての書き込み命令を総チェック。すると、80186以降のCPU(V30含む)には、全汎用レジスタ(16bit×8本)を一度にスタックへ退避する命令が見つかります(ニモニックでPUSHA)。 ここから80286CPUのリアルモード(8086互換)を例にお話しします。80286では、16ビットのデータを連続してメモリに書き込む命令STOSWの消費クロックは3、PUSHAは17です。PUSHAは8本の16ビットレジスタを一気にスタックに退避してくれますから、16バイトの書き込み動作と書き込みポインタの更新を17クロックで実行してくれることになります。対してSTOSWはREPプリフィクスと共に使用することによって、16バイトの書き込みとポインタの更新と回数のカウントを3×8=24クロックで実行します。つまり、24−17=7クロック未満で回数のカウント処理を実現できれば、PUSHA命令を利用することによって、さらなる高速化が実現することになります。
【リスト3】が実際のコーディング例です。さすがにCだとわかりづらいのでアセンブラニモニックで記述してあります。事前にGRCGは設定してあると考えてください。対比用にストリング命令STOSWを使ったものも示します。PUSHAを使用した方はプログラムサイズが大きくなりますが、3割強高速になります。単純計算した消費クロック数だと、上が34,968クロック、下が48,010クロックとなります。実際には命令のプリフェッチキューの状態も影響するため、差はもう少し小さくなると思われます。また、スタックがV-RAMになるようにスタックポインタをセグメントごと書き換えているため、ループの中にその切り替えが必要になっています。当然、スタックを書き換えている間に割り込みが入ってくるとマズい(GRCG作動中のVRAMリードは保証されていない)ので、スタック書き換え中は割り込みを禁止しています。(スタックポインタ'SP'はアドレスの低い方向へ自動更新されるため初期値が80*400になります。) この例ではPUSHAを50回、画面では10ライン分ごとのループになっていますが、このあたりが無難なところでしょう。ループ回数を増やすと高速性が落ちますし、逆に減らすと割り込み禁止期間が長くなって、BGMが途切れたり、マウスの移動がぎこちなくなったりします。 ちなみに、CPUが80386になると、この差は一気に顕著になり、2倍近くなります。実際にテストプログラムを作って調べてみましたが(80386-25MHz)、明らかに体感できる高速性を得られました(正確なデータが残っていないので、当時の記憶のみなのですが)。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 【リスト3】で紹介したような荒技ルーチンは、市販された風雅の製品には使用されていません。なぜなら、STOSW命令を使ったルーチンで十分に高速だからです。では、なぜこのような高速クリアルーチンを考え出したのかというと、企画段階で中止になったリアルタイム3Dアクションゲーム(「ソリッド・ブラスター」という名称もついていました)用に必要だったからなのです。この企画はうりぼう塚原がリーダーになって進めていたもので、80386CPUを搭載したPC-9801シリーズをターゲットにしていました。ポリゴンで描かれた街の中をモビルスーツで駆け回るタイプのロボットアクションで、プロトタイプまでできていたのです。杉之原名人はこの高速クリアルーチンの他にも、ポリゴン描画ルーチンなども作っていました。 ところが、「80286でも遊べなきゃダメ!」との社長命令もあり、そのまま保留となってしまったのです。そうこうしているうちにWindows95&Direct3Dが登場し、幻の企画となりました。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 02:高速矩形領域塗り潰し(BOX FILL) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 処理的には先の画面クリアと似ていますが、いろいろと考慮すべき点が出てくるのが、この矩形の塗り潰し、BOX FILLです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
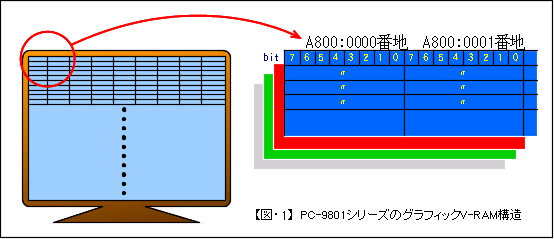
| ごく普通に考えられるのが、同じ長さの水平直線を垂直方向に連続して描画する方法です。これならアルゴリズムも非常に単純ですし、高速に処理できるでしょう。・・・・・ビットマップ型のV-RAMであれば。PC-9801シリーズのグラフィックV-RAMは1ビットが1ピクセルに対応したプレーン型のみなので、この方法が最も高速であるとは一概に言えないのです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
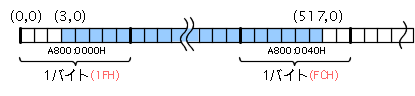
| 【図・1】のように、PC-9801のグラフィックV-RAMは1ビットが1ピクセルに対応したモノクロ画面が4プレーン分重なっています。もうお分かりのように、水平直線を描画するとき、左端と右端の画面座標によって、書き込むバイト(ワード)パターンを適宜変化させる必要があるのです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
例えば、左上座標( 3, 0) 右下座標(517, 199)の塗り潰し矩形を描画する場合を考えてみます。左上X座標が3ということは、【図・2】のようにA800:0000H番地の1バイトのbit4〜0のみを'1'または'0'にする必要があります。また、右下X座標が517ですから、同様に対応するアドレス(A800:0040H番地)の1バイト内のbit7〜2のみを'1'または
ベタ書きできる部分は8086のストリング命令'STOSB/W'を使えば高速処理が実現できるので問題ありませんが、両端のバイトは内部のビット処理が必要です。それも書き込む前のV-RAMのデータと論理演算を行わねばなりません。描画しない部分のビットはそのままにしておかねばなりませんから、適宜特定のビットパターンと'OR'または'AND'をとってやる必要があるわけです。これを描画する色に合わせて4プレーン分繰り返すことになります。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
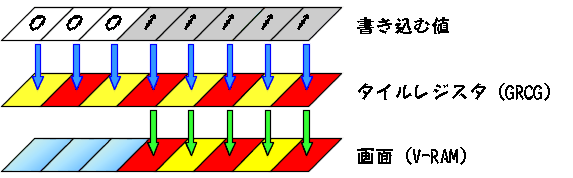
さて、ここでまず考えられる高速化がGRCGを利用する方法です。画面クリアのときはTDWモードを使用しましたが、この場合はRMW(リード・モディファイ・ライト)モードを合わせて使用します。このモードでは、あらかじめタイルレジスタに色パターンを登録しておくと、V-RAMに描き込むバイトのビットが'1'になっている部分はタイルレジスタの内容が描き込まれ、'0'になっている部分は変化しません。つまり、1バイト(8ドット)分の“透過合成表示”ができるわけです。(【図・3】)
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 仮に今回はパレット番号1の色で塗りつぶそうと思えば、GRCGをRMWモードに設定し、タイルレジスタにFFH-00H-00H-00Hと設定しておき、A800:0000H番地に1FH(00011111B)を書き込めばよいのです。次いでGRCGをTDWモードに設定し直し、任意の値を63バイト分連続アドレスに書き込み、再度RMWモードに設定してFCHを書き込めば、1ライン分の描画の終了です。これをY方向に200回繰り返せば塗り潰された矩形描画の完了となります。これだけでかなり高速な描画が実現できます。また、先に述べたように、水平直線描画ルーチンを作っておけば、それを任意回数繰り返し呼び出すだけで実現できるので、とても単純で簡単な方法でもあります。 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| では、ここから高速化を考えます。 先の方法だと、水平ラインを描画する間にGRCGのモードを3回設定しています。これには無駄があります。ここは、次の行を描画するときも最初はRMWモードに設定するので、2行目以降の最初のGRCGモード設定は省略が可能です。ただ、これは単純に水平ラインルーチンを繰り返し呼び出す方法では実現できません。専用のルーチンとして書き下ろす必要があります。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| さらに考えてみると、実はGRCGモードの設定は、全体を通して2回だけで済むことに気付きます。そう、左右両端のみを最初にすべて描画してしまうのです。この方法だと両端のビットパターンをレジスタに設定し、Y方向に一気に書き込んでしまえるので無駄がありません。そして、残った中央部分をTDWモードとストリング命令でまとめて描画するのです。実際、風雅システムの製品に使用されているBOXFILLルーチンはこのアルゴリズムです。 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| しかし、今述べたように、この手法ではX幅の狭い矩形の場合はデメリットはあってもメリットはありません。場合分けのチェックに要する時間がある分だけ、わずかですが遅くなってしまうからです。かといって、そのチェックの必要の有無自体をチェックする(ベタ描画部分が無かったり、1バイト分だけだったりしないか)というのも本末転倒な話です。 このようなときは、敢えて描画ルーチン内でチェックせず、呼び出し側で判断して、X幅の狭い塗り潰し矩形描画専用のルーチンを実行するようにすると効率的です。つまり、「常にX幅の狭い矩形であるとわかっている場合は、それ専用に特化した描画ルーチンを呼び出す」ということなのです。これはグラフィックコントーラチップの“ショートベクタ描画機能”の考え方に似ています。ショートベクタ描画機能とは、最近のグラフィックコントーラチップ(GPU)にまだ残っているか否かは不明ですが、例えば長さ15ドット以下で水平か垂直か斜め45度の直線描画の場合だけ、始点と終点ではなく、始点と方向と長さの情報で超高速に描画する機能をいいます。このような線分はハードウェアだけ(ワイヤードロジック)で簡単に超高速に描画できるため、通常の直線描画とは別の機能としてインプリメントされていた(る)のです。これと同じように、X幅が8ドット以下の矩形描画専用のルーチンや、バイトバウンダリの(左右端のビット操作の必要のない)矩形描画専用のルーチンなどを用意しておき、適宜これらを使い分けるというわけです。
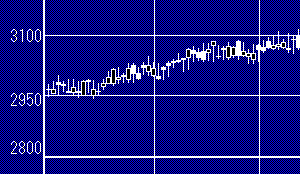
逆にアマランス1&2の戦闘画面の体力ゲージの描画などには通常の矩形描画ルーチンを常に使用すべきです。X幅が8ドット以下の場合だけ別ルーチンを呼び出すようなチェックをいちいち行っていたのでは、巨視的にはわずかながら遅くなることも考えられます。という前に、そもそも頻度が低く、わずかな高速化の意味自体がありません。株価チャートの場合は、タラタラ表示されるか、パッと表示されるかという‘差’を感じられる可能性があります。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| これは矩形塗り潰しに限ったことではないのですが、特に小さな繰り返し処理(=ループ)があるプログラムを記述する場合は、飛び先が偶数アドレスになるようにすると高速化する場合があります。アセンブラで記述する際に、ディレクティブの"EVEN"をループの先頭などに入れておくのです。つまり、ジャンプ命令でプリフェッチキュー(実行されるであろう命令を'先読み'して溜めておく場所)がクリアされた際に、効率良く再充填されるようにするわけです。ごく小さなループの場合、かなり効果のある場合があります。 この手法はごく一般的なもので、32bitCPUにも有効です。もちろん、この場合は「偶数アドレス」ではなく、「4の倍数アドレス」になりますが。また、ループの前に入れると大量のNOP命令(何もするなという命令)が挿入されてしまうので、よく使うサブルーチン(関数)の前に入れておくのが無難でしょう。追補しますが、PentiumIII/IVのように強力な分岐予測機能を備えたCPUではこの手法の効果はほとんどありません。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 高速描画の話。今となっては懐かしい過去の話かもしれません。しかし、温故知新という言葉があるように、中には何かのヒントになったりするものがあるかもしれません。何気なく、おもしろおかしく(?)読んでいただけたら幸いです。ちなみに次回の高速描画の話は「高速ライン描画」の予定です。突然気が変わって、高速文字表示や高速ビットマップ表示になる可能性もあります。なんか、気まぐれなブログみたいなんでですけど・・・・・・(もともとその傾向はありますが) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||